Die Pipeline
Vom Inhalt zum Verdikt in 5 Minuten
Unsere KI-Pipeline analysiert jede politische Behauptung, recherchiert zuverlässige Quellen und liefert ein transparentes, rückverfolgbares Urteil.
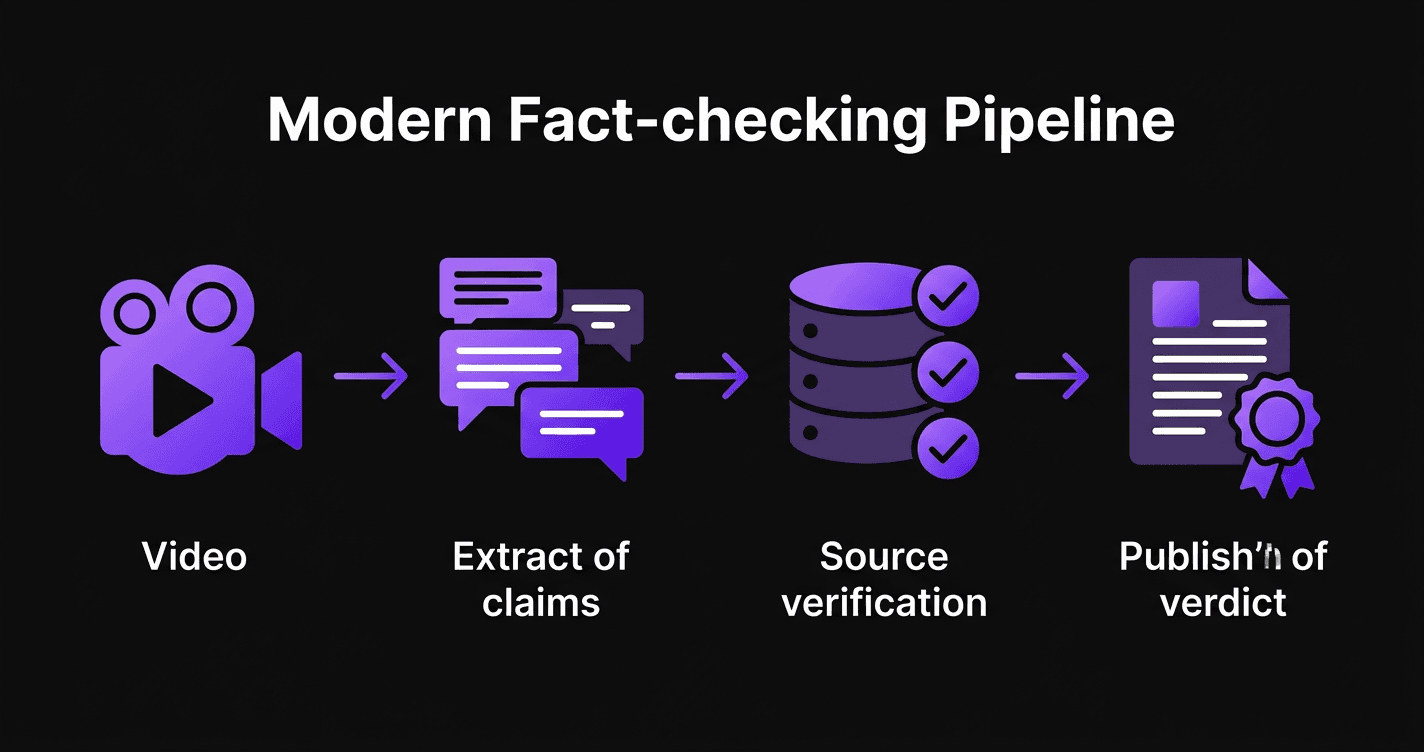
Die Pipeline
Transkription
30s–1minDer Inhalt wird automatisch in Text transkribiert. Wir nutzen Plattform-Untertitel, wenn verfügbar (YouTube, Instagram, TikTok), dann das Whisper-Transkriptionsmodell von OpenAI als Fallback. Der Rohtext wird anschliessend in kohärente thematische Segmente unterteilt.

Kontextanalyse
15–30sVor jeder Verifizierung analysieren wir den Kontext: Wer spricht, in welchem Rahmen (Parlament, Studio, Veranstaltung) und an welchem Datum. Dieser Schritt stellt sicher, dass Behauptungen korrekt kontextualisiert werden.
Behauptungsextraktion
1–2minEin KI-Modell liest jedes Segment und identifiziert überprüfbare Behauptungen - faktische Aussagen, die durch öffentliche Quellen bestätigt oder widerlegt werden können. Meinungen, politische Versprechen und Satire werden als solche erkannt und nicht zur Verifizierung eingereicht.

Quellenrecherche
1–2minFür jede Behauptung recherchiert unser System zuverlässige Quellen im Web: Regierungsseiten, offizielle Institutionen, akademische Publikationen, Referenzmedien. Bis zu 15 Recherche-Iterationen pro Behauptung, um die Beweisabdeckung zu maximieren.
Doppelte KI-Verifizierung
30s–1minJedes Behauptung-Quelle-Paar wird zwei unabhängigen KI-Modellen vorgelegt: einem mehrsprachigen Modell, spezialisiert auf Französisch, Deutsch, Italienisch und Englisch, und einem Hochpräzisionsmodell für englische Quellen. Beide Modelle stimmen unabhängig ab - dasselbe Prinzip wie die Doppelprüfung im Journalismus.
Score & Urteil
SofortEin Gültigkeitsscore (0–100%) wird berechnet, der Quellenübereinstimmung (60%) und Quellenqualität (40%) kombiniert. Dieser Score bestimmt das endgültige Urteil auf einer 8-stufigen Skala von Wahr bis Falsch, plus die Kategorien Meinung und Satire.

Die Urteilsskala
8 Bewertungsstufen, von bestätigten Fakten bis zu erkannter Satire. Jedes Urteil enthält seinen Konfidenzwert und die vollständige Quellenkette.
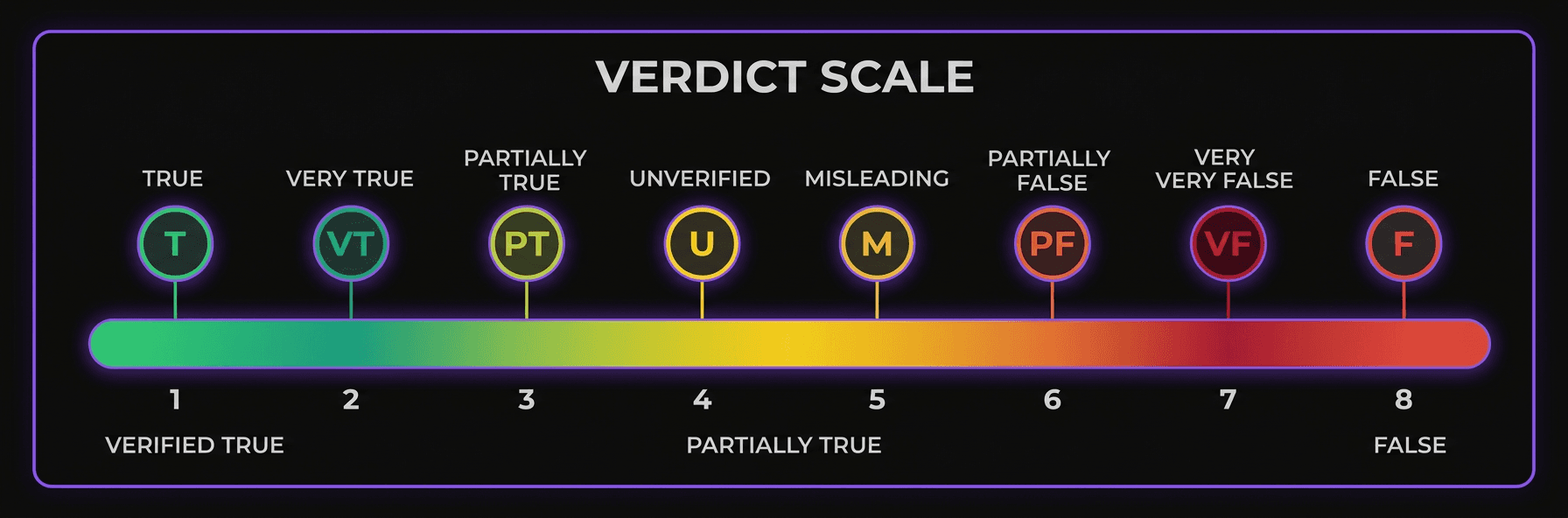
Durch primäre oder offizielle Quellen bestätigt
Mit geringfügigen Nuancen bestätigt
Einige Elemente bestätigt UND einige widerlegt
Technisch korrekt, aber aus dem Kontext gerissen
Durch zuverlässige Quellen widerlegt
Unzureichende Quellen für eine Schlussfolgerung
Werturteil, kein überprüfbarer Fakt
Humoristischer oder satirischer Inhalt erkannt

Unsere Grenzen - in voller Transparenz
Was KI gut kann
- Ein grosses Volumen an Behauptungen schnell verarbeiten (50+ in 5 Minuten)
- Offizielle und institutionelle Quellen finden
- Einen identischen Prozess auf alle Behauptungen anwenden (kein redaktioneller Bias)
Wo KI Schwierigkeiten hat
- Ironie und Satire: Kann einen Witz mit einer faktischen Behauptung verwechseln
- Impliziter Kontext: Verpasst Kontext, den nur ein Fachexperte kennt
- Nuancierte Formulierungen: Konjunktiv und rhetorische Figuren der Politik sind herausfordernd
- Komplexe Statistiken: Mehrfachvergleiche sind schwieriger zu verifizieren
Unser Hauptmodell erreicht 82,3% Genauigkeit bei französischsprachigen Referenz-Benchmarks. Bei spezifischem politischem Text schätzen wir die Genauigkeit auf 77–80%. Deshalb verwenden wir zwei unabhängige Modelle, zeigen immer den Konfidenzwert an, liefern Quellenlinks zur unabhängigen Überprüfung und ermöglichen Journalisten, Urteile zu korrigieren.
Ein Urteil korrigieren
Jedes Urteil ist versioniert. Wird ein Urteil geändert, wird die vorherige Version archiviert - nie gelöscht. Melden Sie einen Fehler über den Button «Dieses Urteil anfechten» in der App oder per E-Mail an corrections@opentruth.ch.
Wir verpflichten uns, jede Meldung innerhalb von 48 Stunden zu prüfen.