Le Pipeline
Du contenu au verdict en 5 minutes
Notre pipeline d'intelligence artificielle analyse chaque affirmation politique, recherche des sources fiables, et produit un verdict transparent et traçable.
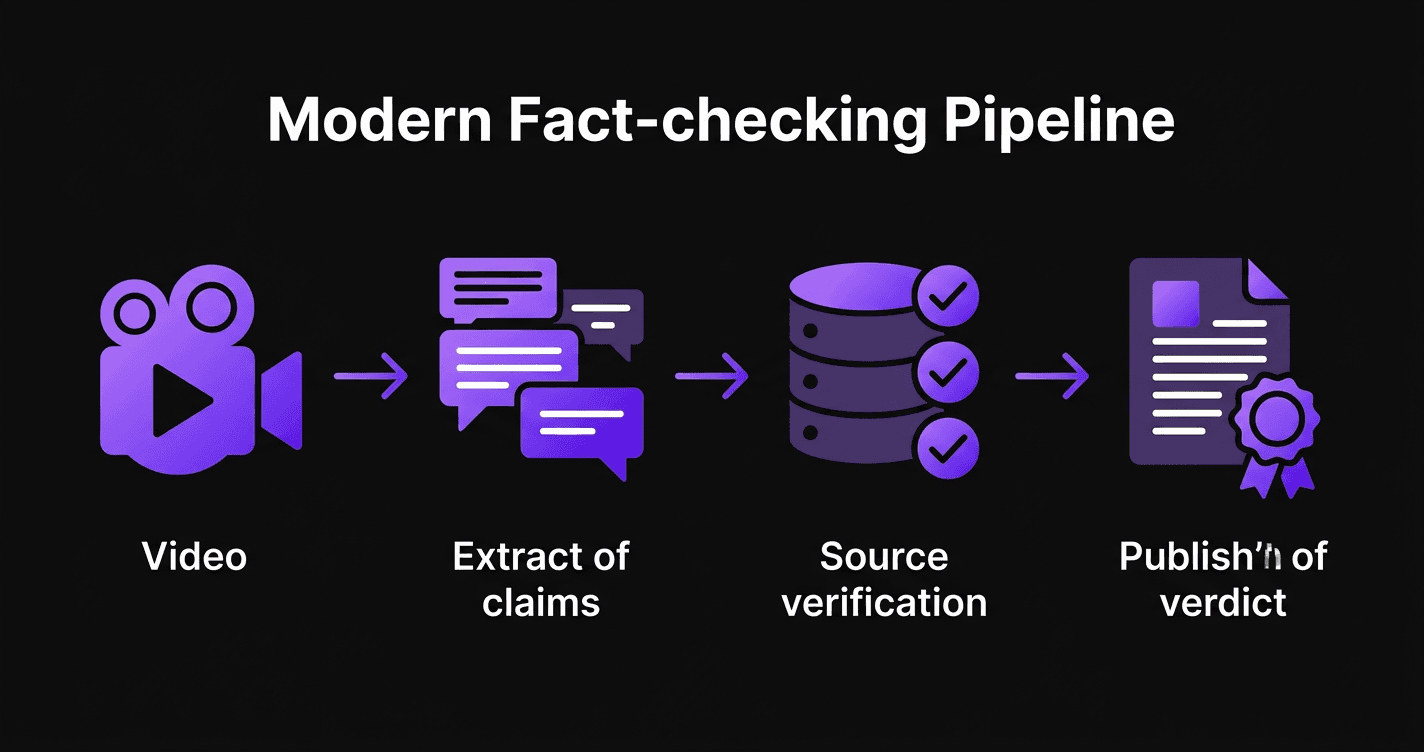
Le Pipeline
Transcription
30s–1minLe contenu est transcrit automatiquement en texte. Nous utilisons les sous-titres de la plateforme lorsqu'ils sont disponibles (YouTube, Instagram, TikTok), puis le modèle de transcription Whisper d'OpenAI en secours. Le texte brut est ensuite découpé en segments thématiques cohérents.

Analyse du contexte
15–30sAvant toute vérification, nous analysons le contexte : qui parle, dans quel cadre (Parlement, studio, meeting), à quelle date. Cette étape permet de contextualiser correctement les affirmations.
Extraction des affirmations
1–2minUn modèle d'intelligence artificielle lit chaque segment et identifie les affirmations vérifiables - les énoncés factuels pouvant être confirmés ou infirmés par des sources publiques. Les opinions, les promesses politiques et la satire sont identifiées comme telles et ne sont pas soumises à vérification.

Recherche de sources
1–2minPour chaque affirmation, notre système recherche des sources fiables sur le web : sites gouvernementaux, institutions officielles, publications académiques, médias de référence. Jusqu'à 15 itérations de recherche par affirmation pour maximiser la couverture des preuves.
Double vérification par IA
30s–1minChaque paire (affirmation, source) est soumise à deux modèles d'IA indépendants : un modèle multilingue spécialisé dans le français, l'allemand, l'italien et l'anglais, et un modèle haute précision spécialisé dans les sources en anglais. Les deux modèles votent indépendamment - le même principe qu'une double relecture en journalisme.
Score & verdict
InstantanéUn score de validité (0–100%) est calculé en combinant la concordance avec les sources (60%) et la qualité des sources (40%). Ce score détermine le verdict final sur une échelle à 8 niveaux, de Vrai à Faux, plus les catégories Opinion et Satire.

L'échelle de verdicts
8 niveaux d'évaluation, des faits confirmés à la satire identifiée. Chaque verdict inclut son score de confiance et sa chaîne de sources complète.
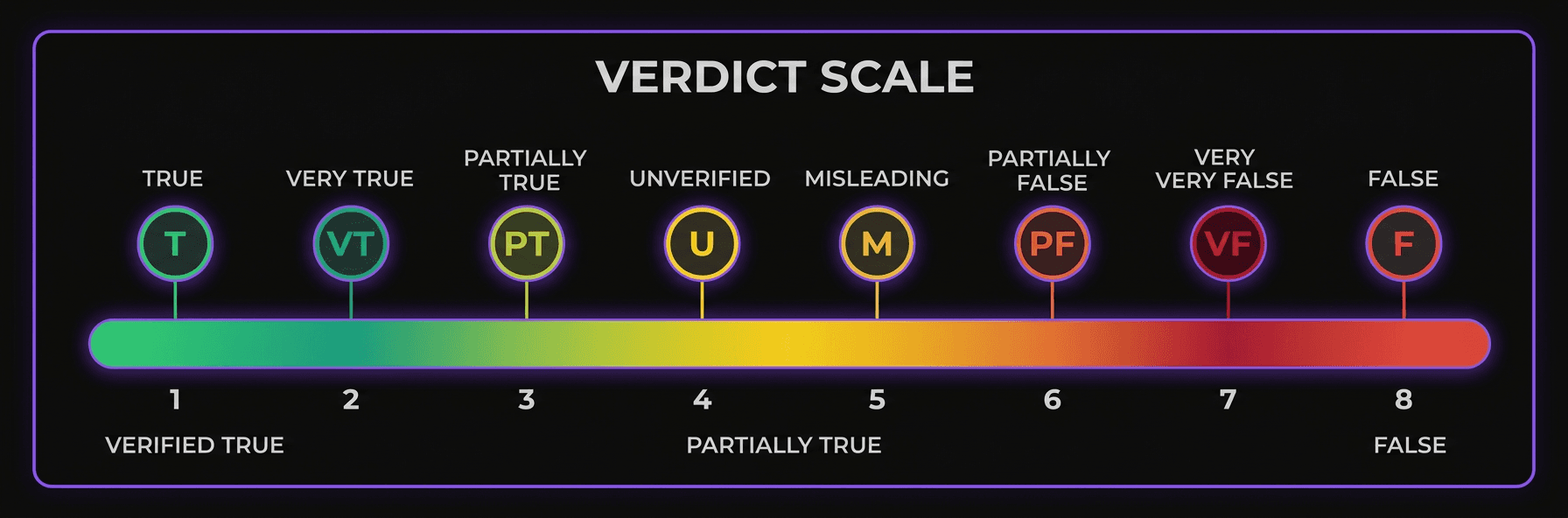
Vérifié par des sources primaires ou officielles
Vérifié avec des nuances mineures
Des éléments confirmés ET des éléments infirmés
Techniquement vrai mais sorti de son contexte
Contredit par les sources fiables
Sources insuffisantes pour conclure
Jugement de valeur, pas un fait vérifiable
Contenu humoristique ou satirique identifié

Nos limites - en toute transparence
Ce que l'IA fait bien
- Traiter un grand volume d'affirmations rapidement (50+ en 5 minutes)
- Trouver des sources officielles et institutionnelles
- Appliquer un processus identique à toutes les affirmations (pas de biais éditorial)
Ce que l'IA fait moins bien
- Ironie et satire : peut confondre une blague avec une affirmation factuelle
- Contexte implicite : manque le contexte que seul un expert du sujet connaît
- Formulations nuancées : le conditionnel et les litotes du français politique sont un défi
- Statistiques complexes : les comparaisons multi-variables sont plus difficiles à vérifier
Notre modèle principal atteint 82,3% de précision sur les benchmarks de référence en français. Sur du texte politique spécifique, nous estimons la précision à 77–80%. C'est pourquoi nous utilisons deux modèles indépendants, affichons toujours le score de confiance, fournissons les liens vers les sources pour vérification indépendante, et permettons aux journalistes de modifier les verdicts.
Corriger un verdict
Chaque verdict est versionné. Si un verdict est modifié, l'ancien est archivé - jamais supprimé. Signalez une erreur via le bouton « Contester ce verdict » dans l'app ou par email à corrections@opentruth.ch.
Nous nous engageons à examiner chaque signalement sous 48 heures.
Prêt à vérifier le discours politique ?
Rejoignez la liste d'attente et soyez parmi les premiers à découvrir la vérification par IA.