The Pipeline
From content to verdict in 5 minutes
Our AI pipeline analyzes every political claim, searches reliable sources, and produces a transparent, traceable verdict.
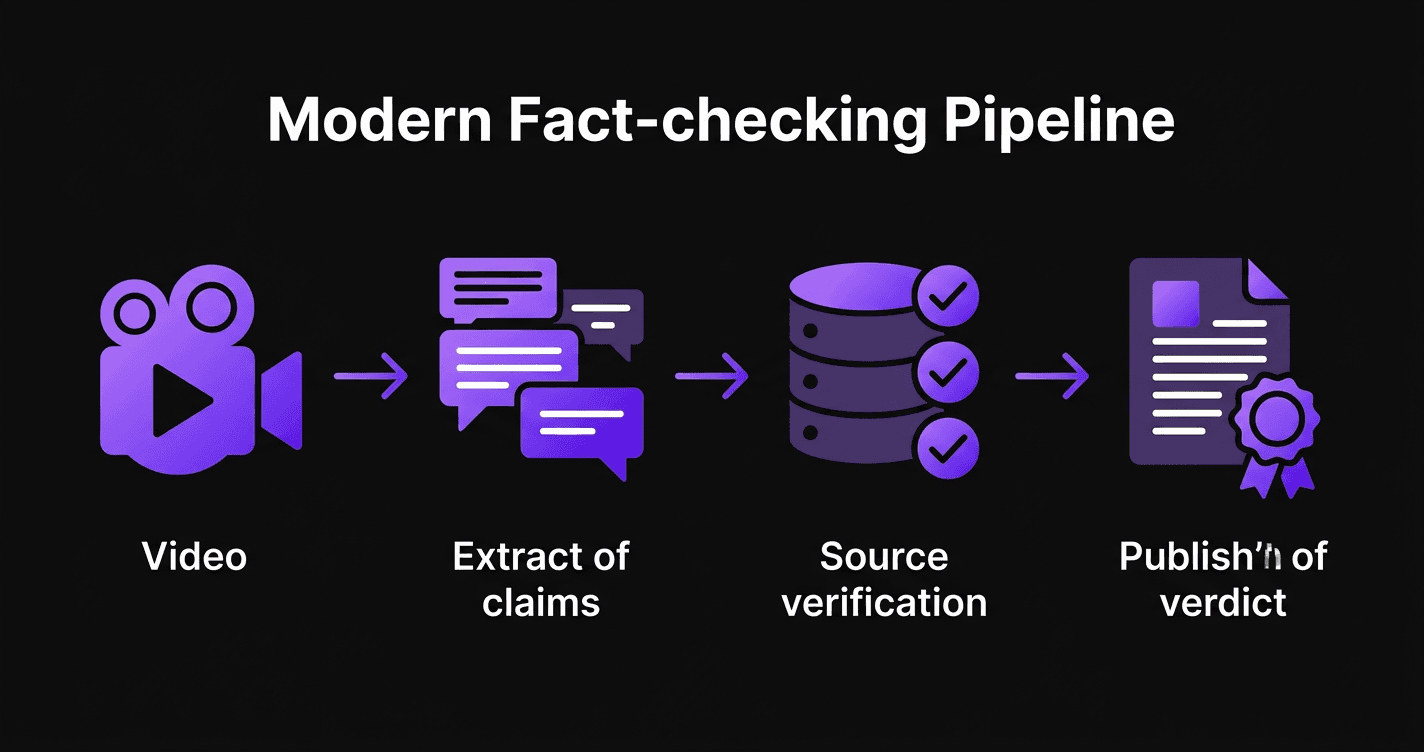
The Pipeline
Transcription
30s–1minThe content is automatically transcribed to text. We use platform subtitles when available (YouTube, Instagram, TikTok), then OpenAI's Whisper transcription model as fallback. The raw text is then split into coherent thematic segments.

Context analysis
15–30sBefore any verification, we analyze the context: who is speaking, in what setting (Parliament, studio, rally), and on what date. This step ensures claims are correctly contextualized.
Claim extraction
1–2minAn AI model reads each segment and identifies verifiable claims - factual statements that can be confirmed or refuted by public sources. Opinions, political promises, and satire are identified as such and are not submitted for verification.

Source research
1–2minFor each claim, our system searches reliable sources on the web: government sites, official institutions, academic publications, reference media. Up to 15 research iterations per claim to maximize evidence coverage.
Dual AI verification
30s–1minEach claim-source pair is submitted to two independent AI models: a multilingual model specialized in French, German, Italian and English, and a high-precision model specialized in English sources. Both models vote independently - the same principle as double review in journalism.
Score & verdict
InstantA validity score (0–100%) is calculated combining source concordance (60%) and source quality (40%). This score determines the final verdict on an 8-level scale from True to False, plus Opinion and Satire categories.

The verdict scale
8 levels of assessment, from confirmed facts to identified satire. Each verdict includes its confidence score and full source chain.
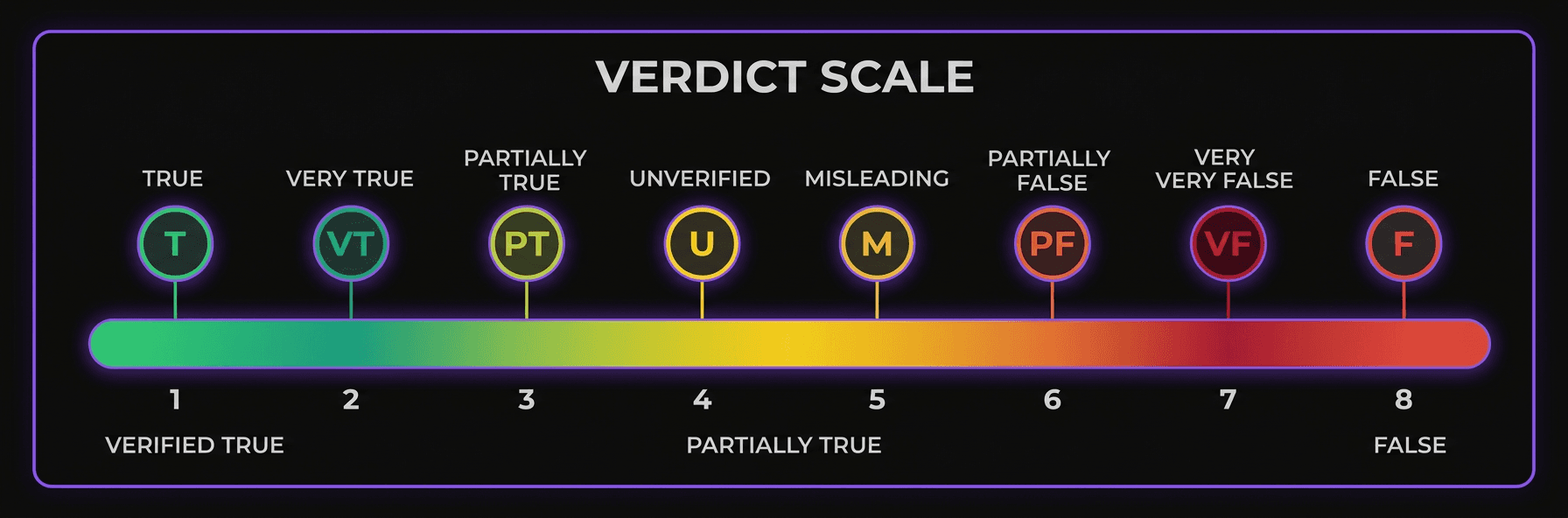
Confirmed by primary or official sources
Confirmed with minor nuances
Some elements confirmed AND some refuted
Technically true but taken out of context
Contradicted by reliable sources
Insufficient sources to conclude
Value judgment, not a verifiable fact
Humorous or satirical content identified

Our limitations - in full transparency
What AI does well
- Process a large volume of claims quickly (50+ in 5 minutes)
- Find official and institutional sources
- Apply an identical process to every claim (no editorial bias)
What AI finds harder
- Irony and satire: may confuse a joke with a factual claim
- Implicit context: misses context only a subject expert would know
- Nuanced phrasing: French political conditionals and litotes are challenging
- Complex statistics: multi-variable comparisons are harder to verify
Our main model achieves 82.3% accuracy on French-language benchmarks. On specific political text, we estimate accuracy at 77–80%. That's why we use two independent models, always display the confidence score, provide source links for independent verification, and allow journalists to correct verdicts.
Correcting a verdict
Every verdict is versioned. If a verdict is modified, the previous version is archived - never deleted. Report an error via the 'Contest this verdict' button in the app or by email at corrections@opentruth.ch.
We commit to reviewing every report within 48 hours.